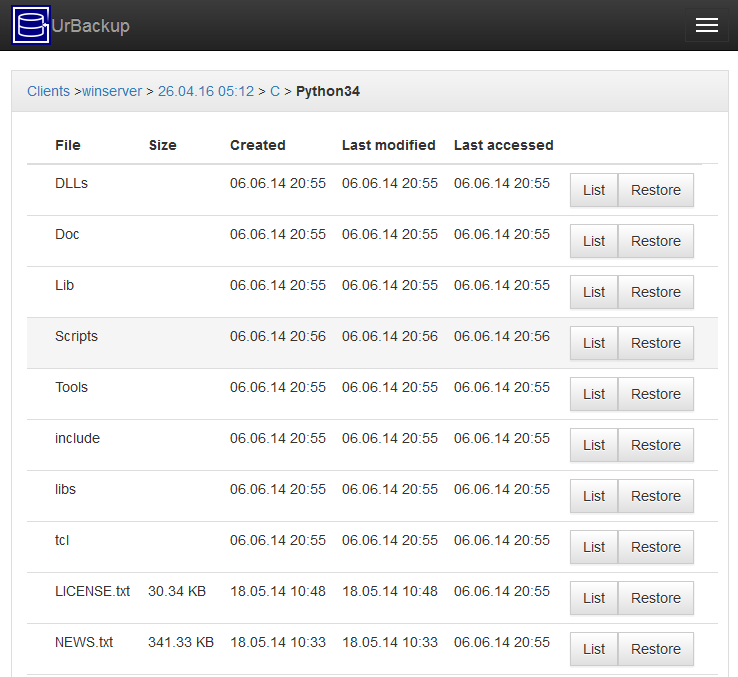
W eb interface modernization. The web interface was a little bit utilitarian which gave many people the wrong impression. With the help of mombojuice the web interface was improved such that it looks much more modern and professional. Many small improvements were made as well. For example the dates are now formatted according to browser locale, backups can be started via drop-down menu and the live log of a running backup can be directly accessed from the activities screen.
eb interface modernization. The web interface was a little bit utilitarian which gave many people the wrong impression. With the help of mombojuice the web interface was improved such that it looks much more modern and professional. Many small improvements were made as well. For example the dates are now formatted according to browser locale, backups can be started via drop-down menu and the live log of a running backup can be directly accessed from the activities screen.
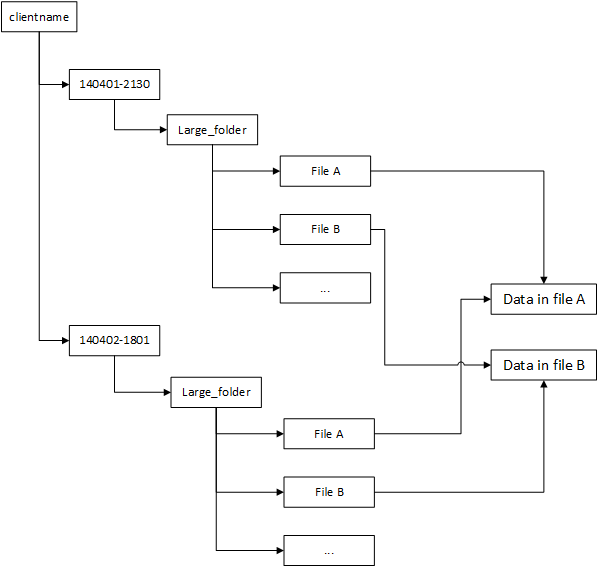
Improved file deduplication. Completely reworked the file deduplication and file backup statistics calculation. This should be much faster, scalable and reliable now.
File 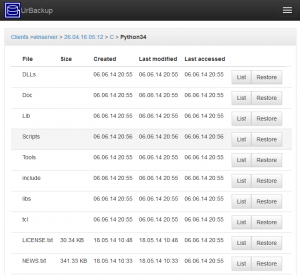 backup improvements. File meta-data such as last modified time and file permissions are now backed up on all supported client systems (Windows, Linux, Mac OS X). Supporting more exotic file system features such as sparse files UrBackup is now a fully featured file backup solution.
backup improvements. File meta-data such as last modified time and file permissions are now backed up on all supported client systems (Windows, Linux, Mac OS X). Supporting more exotic file system features such as sparse files UrBackup is now a fully featured file backup solution.
File backup restore. To restore the file meta-data UrBackup has now an integrated file restore. The file restore reuses client-side hashes, if present, and transfers only differences, such that restoring folders with only few changes since the restored backup is fast.
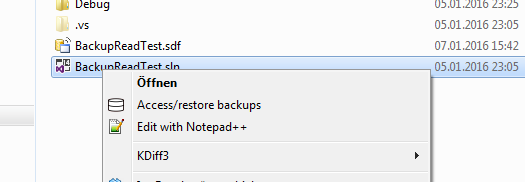
 Direct backup access. If configured, the backed up file permissions are used to allow clients direct access to their files with only minimal configuration. On Windows there is a shortcut in Explorer which directly opens the relevant/file folder in the browser. There is a new list view which shows a file/folder in all backups. For files, hashes are used to show when the file content changed (versions).
Direct backup access. If configured, the backed up file permissions are used to allow clients direct access to their files with only minimal configuration. On Windows there is a shortcut in Explorer which directly opens the relevant/file folder in the browser. There is a new list view which shows a file/folder in all backups. For files, hashes are used to show when the file content changed (versions).
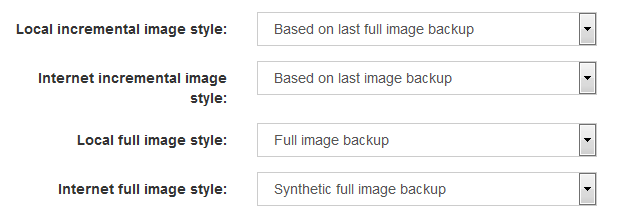
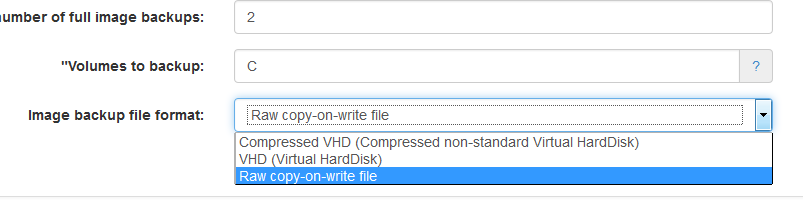
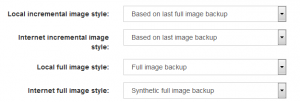 Image backup improvements. UrBackup supports GPT formatted disks now and the restore CD boots on UEFI firmware devices (also with secure boot enabled). In combination with btrfs, UrBackup supports an incremental forever style image backup and image backups over 2TB. For VHD/VHDZ UrBackup has now settings to base incremental backups on the last or last full image backup. Full image backups can be configured to be synthetic full backups transferring only changes since the last image backup.
Image backup improvements. UrBackup supports GPT formatted disks now and the restore CD boots on UEFI firmware devices (also with secure boot enabled). In combination with btrfs, UrBackup supports an incremental forever style image backup and image backups over 2TB. For VHD/VHDZ UrBackup has now settings to base incremental backups on the last or last full image backup. Full image backups can be configured to be synthetic full backups transferring only changes since the last image backup.
Significant security improvements. Forward secrecy for Internet clients via ECDH and Internet client security improvement by using AES-GCM. Switch from DSA to ECDSA for client update and server identity signatures. Web server/restore CD login now uses PBKDF2.
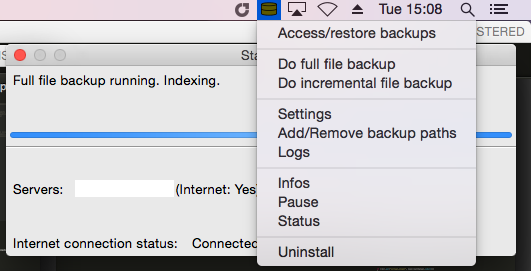
Mac OS X client. There is now a UrBackup Client for Mac OS X. This client is fully featured, excluding image backup (like Linux client). The Mac OS X client can be used as a technically superior backup solution to Time Machine.
a UrBackup Client for Mac OS X. This client is fully featured, excluding image backup (like Linux client). The Mac OS X client can be used as a technically superior backup solution to Time Machine.
Improved command line. Mainl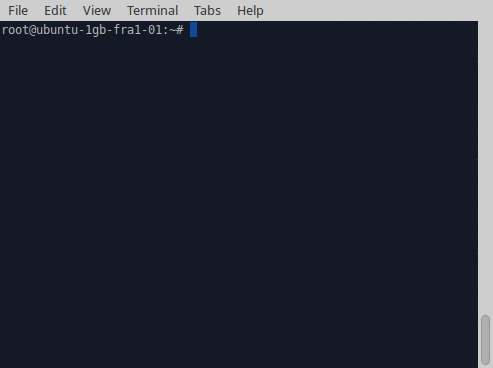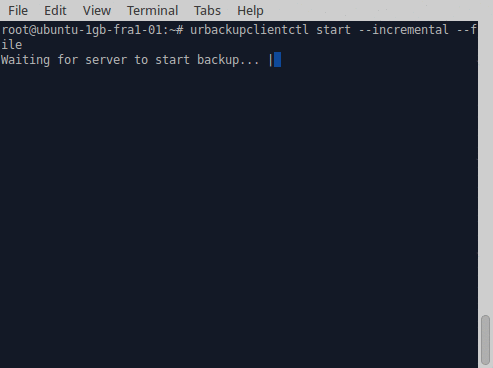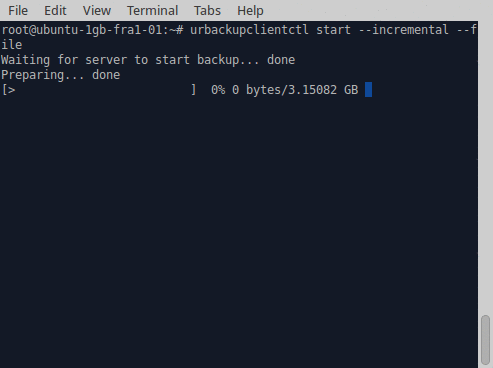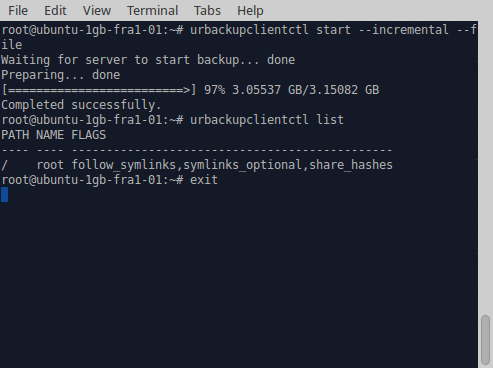 y for Linux all command line usage has been significantly improved. This includes the command line client (urbackupclientctl), the server command line (urbackupsrv) and the restore client.
y for Linux all command line usage has been significantly improved. This includes the command line client (urbackupclientctl), the server command line (urbackupsrv) and the restore client.
Linux file system snapshotting. Snapshotting now also works on Linux and is fully integrated. A portable Linux client includes snapshot scripts for LVM, dattobd and btrfs which work without changes in most cases.
Lots of other changes. Proper symbolic link backup. Virtual clients allow you to backup different sets of files at different intervals and max/min amounts. Simultaneous image and file backups. Different backup speeds and backup intervals at different times. Improved Internet transfer compression. New hashing method where the server only needs to hash changed parts of a file.