
If you get an error like this during image backups:
Error on client occurred: Error while reading from shadow copy device (1). Data error (cyclic redundancy check).
Or like this during a file backup:
Error getting file patch for “x/y/z.file” from CLIENT. Errorcode: ERRORCODES (11)
Remote Error: Reading from file failed. System error code: 23
Or you get the same error while copying/accessing a file in any program (Windows Explorer, etc.) you have damaged sectors on your hard disk. One way to confirm this is to have a look at your disk’s S.M.A.R.T. values (e.g. with SpeedFan; please comment with a better alternative if you have any).
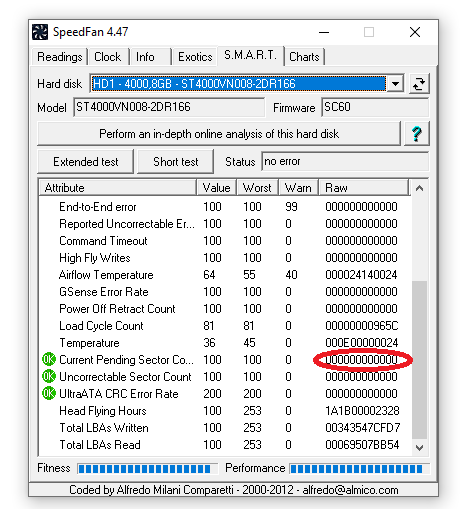
The raw value of “Current pending sector count” should be greater than zero.
As an explanation: Your hard disk is designed such that the probability that each sector becomes unreadable is really low. Nevertheless, it is still possible and expected during a hard disk’s lifetime, as such the hard disk is engineered to handle this failure case. The hard disk has a few spare sectors. If a sector becomes damaged, the hard disk replaces this sector with one of those spare sectors. The good case is that the hard disk detects that a sector has problems while still being able to read the data in this sector (e.g. by retrying or using storage redundancy). In this case it can read the data, replace the sector with a spare one, write the data to the spare sector and use the spare sector from then on (S.M.A.R.T. value “Reallocated Sector Count” is increased by one).
If it cannot read the data it has to return a error saying that it cannot read the sector (and increase “Current Pending Sector Count” by one). The next time the sector is written to, it’ll write the data to a spare sector, then replace the damaged sector with the spare one (and decrease “Current Pending Sector Count” by one while increasing “Reallocated Sector Count” by one).
The error being returned by Windows if the hard disk says a sector is unreadable is “Data error (cyclic redundancy check)” (system error code 23).
If you don’t have a copy of the damaged sector you have lost data. You could
retry a few times. Put the hard disk in a freezer and then retry or something,
but chances are it won’t work.
This doesn’t mean your hard disk is completely broken. It may be an indication that it is going to break completely soon, but you also might have just been unlucky during normal operation.
How to fix it
If the error message includes a file path, replace the file with a backup copy. If you don’t have a backup copy, you can either delete the whole file, or use the scrub tool below to only delete the damaged parts of the file (if it is a movie file or an image it might be mostly okay).
If it is occurring during image backups, the scrub tool has the option to find out which files are damaged. You can then either replace the files with backup copies, delete the files or let the scrub tool delete the damaged parts of the file.
If the damaged files are Windows system files, they might get fixed by running a system integrity check. Open an admin console (WINDOWS + X then “Windows PowerShell (Administrator)”) then enter “sfc /scannow”.
Scrub tool
The UrBackup client (starting with 2.4.x) includes a tool that scans a whole disk, then lists the damaged files, then has the option to delete damaged parts of a file.
- Download and install UrBackup client from https://www.urbackup.org/download.html#client_windows
- Go to “C:\Program Files\UrBackup” in Explorer
- Right-click “scrub_disk.bat” then select “Run as Administrator”
- Select the volume you want to repair
- If it finds unreadable sectors it asks if you want to list the damaged files (this might take some time) and if you want to delete those unreadable sectors